
领取口令:免费查重

基于大数据的高校毕业生就业决策支持系统设计
来源:论文查重 时间:2019-11-21 17:04:09
摘 要: 大数据背景下, 传统的决策支持系统很难适应海量数据的存储、 处理以及实时决策的需求。 利用大数据技术建立
基于 Hadoop 的大数据决策支持系统体系结构, 依据这个体系结构, 结合高校毕业生就业决策支持系统的具体需求, 建立基于大
数据的高校毕业生就业决策支持系统, 该系统对高校毕业生的就业以及高校专业的设置、 招生计划的制定都有较好的指导作用。
关键词: 大数据; Hadoop; 决策支持系统
0 引 言
大学生的就业一直都是社会各界普遍关注的社会问题。
教育部颁布的《教育部关于做好 2019 届全国普通高等学校
毕业生就业创业工作的通知》 明确指出“促进高校毕业生就
业创业, 事关广大群众切身利益, 事关社会和谐稳定, 事关
高等教育健康发展” [1]。
随着我国教育信息化步伐的不断加快, 各高校基本上都
建立了与毕业生就业相关的管理信息系统, 通过信息化手段
服务于毕业生就业工作, 但就目前应用状况而言, 这些系统
的功能基本停留于简单的信息采集、 查询等层面, 对诸如毕
业生的就业信息分析、 就业趋势的预测以及个性化就业推荐
服务等深层次的应用, 更多流于形式。 因此, 这些系统对指
导高校毕业生的就业及预测未来的就业趋势发挥的作用比较
有限。 目前高校就业管理部门对毕业生的就业指导主要依赖
于个人的主观经验, 导致就业指导的专业性不足。 如何提高
就业指导决策的科学性和专业性成为高校就业指导工作面临
的首要问题。
随着“大数据” 时代的来临, 大数据技术在社会各领域
中日益发挥着重要作用, 决策者的决策基于数据和分析而做出, 而并非基于经验和直觉。 将大数据技术运用到高校毕业
生就业领域, 对于为高校毕业生的就业提供决策支持是十分
有益的。
1 决策支持系统简介
决策支持系统(Decision Support System, DSS) 是从
管理信息系统发展而来的, 利用数据和模型, 通过人机交互
的方式辅助决策者解决半结构化和非结构化决策问题的信息
系统。 传统的决策支持系统由数据库子系统、 模型库子系
统、 人机交互子系统三个部分构成 [2], 如图 1 所示。
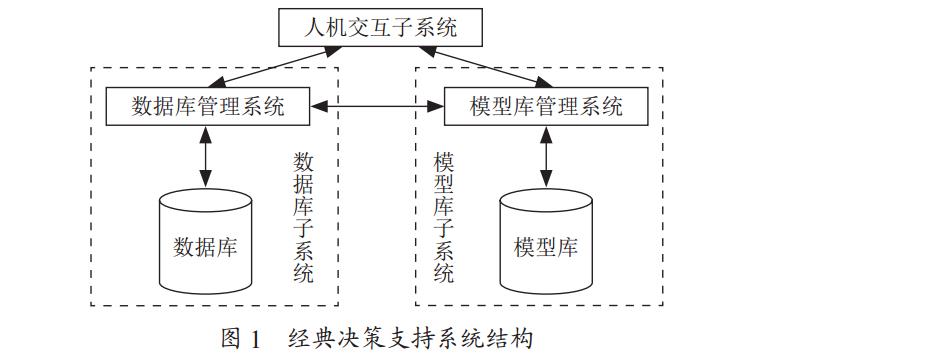 数据库子系统: 由数据库和数据库管理系统构成, 存储
和管理了决策支持系统所需的各类数据。
模型库子系统: 由模型库、 模型库管理系统构成, 存储
和管理决策支持系统中的各类决策模型。
人机交互子系统: 用户通过该子系统与决策支持系统中的数据库管理系统, 模型库管理系统对话, 以查询、 操作数
据库, 或运行模型获得结果。
2 基于 Hadoop 的大数据决策支持系统
2.1 基于大数据的决策支持系统需要解决的问题
“大数据” 时代的到来对决策支持系统的发展提出了
许多新的要求, 这些要求主要体现在大数据环境下决策支
持系统中海量数据的存储、 处理以及实时决策这三个方面。
传统的决策支持系统所包含的数据多为结构化数据, 这些数
据一般都存储在单结点的关系数据库中, 但关系数据库在非
结构化数据的存储和数据库的扩展性方面存在不足, 不适合
在大数据环境下进行包含多种非结构化数据的海量数据的存
储和处理。 由于传统的决策支持系统处理的数据量小, 数据
的查询和模型库模型算法的运行的时间都很短, 因此传统的
决策支持系统仅能满足数据量较小的情况下用户实时决策的
需求。 在大数据环境下, 由于涉及的数据量巨大, 数据的查
询和模型算法的运行都需要花费很多时间, 因此传统关系数
据库和模型库中的模型算法已无法满足决策者实时决策的需
求, 需要从数据的存储方式以及模型库模型的实现算法两方
面解决基于大数据的决策支持系统的实时决策需求。
2.2 建立基于 Hadoop 的大数据决策支持系统体系
结构
Hadoop 是由 Apache 基金会所开发的分布式系统基础架
构, 其核心是能够实现海量数据存储的 HDFS(分布式文件存
储系统) 以及能解决大数据的并行处理、 计算的 MapReduce
(分布式并行计算框架) [3]。 Hadoop 发展至今, 已成为构建
大数据平台的主流技术, 除了 HDFS 和 MapReduce, 还有许
多基于 Hadoop 的软件, 为其提供多方面的业务支撑。 如:
数据仓库 Hive; NoSQL 数据库 HBase; 机器学习算法库
Mahout; 数据迁移工具 Sqoop 以及大数据可视化工具(R
语言, Python 语言) 等。
依据“基于大数据的决策支持系统” 对海量数据的存储、
处理以及实时决策要求, 利用 Hadoop 框架和相关技术采用
分层设计方法对“基于大数据的决策支持系统” 的体系结构
进行设计 [4, 5], 整个系统体系结构包括四层: 基础层、 数据
存储层、 分析层、 决策支持层, 系统结构如图 2 所示。
数据库子系统: 由数据库和数据库管理系统构成, 存储
和管理了决策支持系统所需的各类数据。
模型库子系统: 由模型库、 模型库管理系统构成, 存储
和管理决策支持系统中的各类决策模型。
人机交互子系统: 用户通过该子系统与决策支持系统中的数据库管理系统, 模型库管理系统对话, 以查询、 操作数
据库, 或运行模型获得结果。
2 基于 Hadoop 的大数据决策支持系统
2.1 基于大数据的决策支持系统需要解决的问题
“大数据” 时代的到来对决策支持系统的发展提出了
许多新的要求, 这些要求主要体现在大数据环境下决策支
持系统中海量数据的存储、 处理以及实时决策这三个方面。
传统的决策支持系统所包含的数据多为结构化数据, 这些数
据一般都存储在单结点的关系数据库中, 但关系数据库在非
结构化数据的存储和数据库的扩展性方面存在不足, 不适合
在大数据环境下进行包含多种非结构化数据的海量数据的存
储和处理。 由于传统的决策支持系统处理的数据量小, 数据
的查询和模型库模型算法的运行的时间都很短, 因此传统的
决策支持系统仅能满足数据量较小的情况下用户实时决策的
需求。 在大数据环境下, 由于涉及的数据量巨大, 数据的查
询和模型算法的运行都需要花费很多时间, 因此传统关系数
据库和模型库中的模型算法已无法满足决策者实时决策的需
求, 需要从数据的存储方式以及模型库模型的实现算法两方
面解决基于大数据的决策支持系统的实时决策需求。
2.2 建立基于 Hadoop 的大数据决策支持系统体系
结构
Hadoop 是由 Apache 基金会所开发的分布式系统基础架
构, 其核心是能够实现海量数据存储的 HDFS(分布式文件存
储系统) 以及能解决大数据的并行处理、 计算的 MapReduce
(分布式并行计算框架) [3]。 Hadoop 发展至今, 已成为构建
大数据平台的主流技术, 除了 HDFS 和 MapReduce, 还有许
多基于 Hadoop 的软件, 为其提供多方面的业务支撑。 如:
数据仓库 Hive; NoSQL 数据库 HBase; 机器学习算法库
Mahout; 数据迁移工具 Sqoop 以及大数据可视化工具(R
语言, Python 语言) 等。
依据“基于大数据的决策支持系统” 对海量数据的存储、
处理以及实时决策要求, 利用 Hadoop 框架和相关技术采用
分层设计方法对“基于大数据的决策支持系统” 的体系结构
进行设计 [4, 5], 整个系统体系结构包括四层: 基础层、 数据
存储层、 分析层、 决策支持层, 系统结构如图 2 所示。
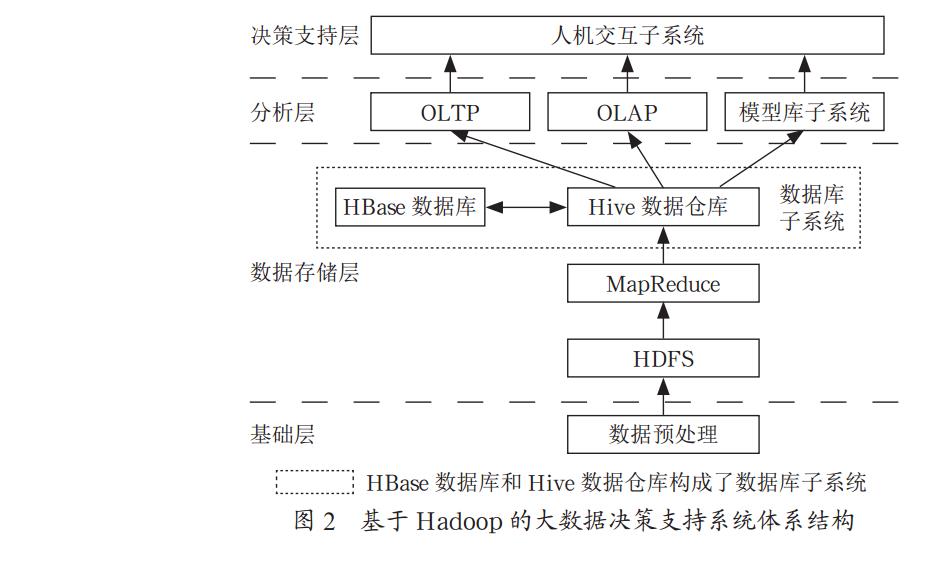 基础层: 实现决策支持系统所需的各类数据的抽取、 清
理、 转换等预处理工作。
数据存储层: 实现决策系统所需的各类数据的存取、
管理功能。 为解决海量数据的存储, 数据存储层将基础层预
处理后的数据存储到 Hadoop 的 HDFS 中。 为提高数据库
子系统的查询、 处理速度, 在数据存储层利用 Hive 数据仓
库结合 HBase 宽表数据库, 为基于大数据的决策支持系统
构建一个低延迟的数据库子系统。 Hive 是基于 Hadoop 的
数据仓库, 它能使用类 SQL 的 HiveQL(HQL) 语言实现
数据查询操作, 能使不熟悉 MapReduce 的用户利用 HQL
处理和计算 HDS 上的结构化数据, 因此十分适合针对数据
仓库的 OLAP(联机分析处理) 操作。 由于 Hadoop 通常
都有较高的延迟, 因此 Hive 不适合低延时的实时应用。
HBase 是面向列存储的 NoSQL 数据库, 可以存储结构化和
非结构化数据, 可进行快速查询, 但 HBase 数据库不支持
类 SQL 语句, 因此可以将 Hive 和 HBase 结合, 将基于大
数据决策支持中所需的随机查询数据存入 HBase 数据库,
通过 Hive 利用 HQL 语句对 HBase 数据库存储的数据进行
OLTP(联机事务处理) 操作, 以满足基于大数据决策支持
实时决策的需要。
分析层: 提供决策模型, 以及针对数据库和数据仓库
的 OLTP 和 OLAP 操作, 辅助决策者决策。 Mahout 中提
供了许多可扩展的机器学习领域经典算法, 它在最近版本中
提供了对 Hadoop 的支持, 利用 Mahout 中这些经典算法结
合决策支持系统的决策需求, 可构建模型库的决策模型, 在
Hadoop 框架下运行, 提高决策模型的运算速度, 满足基于
大数据决策支持实时决策的需要。
决策支持层: 这是一个人机交互子系统, 决策者可通过
人机交互调用分析层中模型库的模型, 对数据库子系统中的
数据执行 OLTP/OLAP 操作, 获取决策所需的信息, 辅助
决策者进行决策。
3 基于大数据的高校毕业生就业决策支持系统
3.1 可行性
大数据技术为提升高校就业指导决策的科学性提供了可
能。 目前各高校建立的与毕业生就业相关的管理信息系统中
已存储了大量历届毕业生就业的相关信息, 各高校的就业信
息网上也发布了最新的招聘信息。 这些信息数据量大, 数据
类型多样, 既有结构化数据也包含了许多半结构化和非结构
化数据, 且每年都有大量的毕业生信息以及招聘信息产生,
数据的增长速度非常快, 但这些数据的价值密度低。 因此,
目前大多数高校所掌握的和高校毕业生就业有关的数据信息
具备了大数据的“4V” 特征, 即数据体量巨大(Volume)、
数据类型繁多(Variety)、 产生速度快(Velocity)、 价值
密度低(Value) [6]。
当前大数据技术的飞速发展, 为大数据的存储、 处理提
供了可能。 以 Hadoop 为代表的大数据技术为基于大数据的
高校毕业生就业决策支持系统的设计提供了技术支持。 对基
于大数据的高校毕业生就业决策支持系统可基于 Hadoop 的
框架来实现。
3.2 基于大数据的高校毕业生就业决策支持系统的
功能需求分析
(1) 对高校毕业生就业情况进行分析, 产生大学毕业
生就业质量年度分析报告;
(2) 对高校毕业生就业的热点和发展趋势分析;
(3) 对就业整体趋势进行预测;
(4) 智能化的推荐, 为高校毕业生进行个性化就业推
荐 [7-9]。
3.3 基于大数据的高校毕业生就业决策支持系统的
设计
高校毕业生就业决策支持系统按照“基于 Hadoop 的大
数据决策支持系统” 体系结构进行设计, 其基础层、 数据存
储层、 分析层和决策支持层的具体功能如下:
基础层: 数据来源于毕业生生源信息数据库, 毕业生就
业信息数据库, 就业信息网站的招聘信息, 双选会, 公务员、事业单位的招考信息等, 这些信息数据既包含了关系数据库
中存储的结构化数据, 也包含了网站上的半结构化、 非结构
化信息。 基础层需要对这些异构的数据进行采集、 清理、 预
处理, 再将其输出到数据存储层的 HDFS 中。
数据存储层: 数据存储层不仅要能够存储海量的数据,
更重要的是为其上层——分析层能够更好地对数据进行分
析提供支持。 数据仓库是为了决策需要而设计的, 是面向
主题的、 集成的。 数据仓库的设计是数据存储层设计的重点。
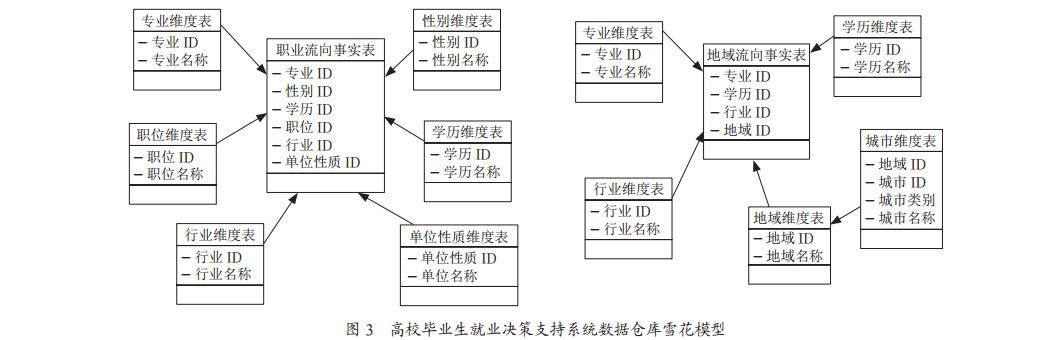
在本系统中, 依据其功能需求, 设定数据仓库面向毕业生
就业的职业流向和毕业生就业的地域流向两大主题。 数据
仓库的逻辑结构采用雪花模型进行设计, 如图 3 所示, 它
包括两个基本的元素: 事实表和维度表, 事实表用来存放
要分析的全部数据, 维度表中的维度是分析问题的角度(例
如: 性别、 专业、 学历层次、 地域、 职位、 行业、 就业单
位的性质等)。
基础层: 实现决策支持系统所需的各类数据的抽取、 清
理、 转换等预处理工作。
数据存储层: 实现决策系统所需的各类数据的存取、
管理功能。 为解决海量数据的存储, 数据存储层将基础层预
处理后的数据存储到 Hadoop 的 HDFS 中。 为提高数据库
子系统的查询、 处理速度, 在数据存储层利用 Hive 数据仓
库结合 HBase 宽表数据库, 为基于大数据的决策支持系统
构建一个低延迟的数据库子系统。 Hive 是基于 Hadoop 的
数据仓库, 它能使用类 SQL 的 HiveQL(HQL) 语言实现
数据查询操作, 能使不熟悉 MapReduce 的用户利用 HQL
处理和计算 HDS 上的结构化数据, 因此十分适合针对数据
仓库的 OLAP(联机分析处理) 操作。 由于 Hadoop 通常
都有较高的延迟, 因此 Hive 不适合低延时的实时应用。
HBase 是面向列存储的 NoSQL 数据库, 可以存储结构化和
非结构化数据, 可进行快速查询, 但 HBase 数据库不支持
类 SQL 语句, 因此可以将 Hive 和 HBase 结合, 将基于大
数据决策支持中所需的随机查询数据存入 HBase 数据库,
通过 Hive 利用 HQL 语句对 HBase 数据库存储的数据进行
OLTP(联机事务处理) 操作, 以满足基于大数据决策支持
实时决策的需要。
分析层: 提供决策模型, 以及针对数据库和数据仓库
的 OLTP 和 OLAP 操作, 辅助决策者决策。 Mahout 中提
供了许多可扩展的机器学习领域经典算法, 它在最近版本中
提供了对 Hadoop 的支持, 利用 Mahout 中这些经典算法结
合决策支持系统的决策需求, 可构建模型库的决策模型, 在
Hadoop 框架下运行, 提高决策模型的运算速度, 满足基于
大数据决策支持实时决策的需要。
决策支持层: 这是一个人机交互子系统, 决策者可通过
人机交互调用分析层中模型库的模型, 对数据库子系统中的
数据执行 OLTP/OLAP 操作, 获取决策所需的信息, 辅助
决策者进行决策。
3 基于大数据的高校毕业生就业决策支持系统
3.1 可行性
大数据技术为提升高校就业指导决策的科学性提供了可
能。 目前各高校建立的与毕业生就业相关的管理信息系统中
已存储了大量历届毕业生就业的相关信息, 各高校的就业信
息网上也发布了最新的招聘信息。 这些信息数据量大, 数据
类型多样, 既有结构化数据也包含了许多半结构化和非结构
化数据, 且每年都有大量的毕业生信息以及招聘信息产生,
数据的增长速度非常快, 但这些数据的价值密度低。 因此,
目前大多数高校所掌握的和高校毕业生就业有关的数据信息
具备了大数据的“4V” 特征, 即数据体量巨大(Volume)、
数据类型繁多(Variety)、 产生速度快(Velocity)、 价值
密度低(Value) [6]。
当前大数据技术的飞速发展, 为大数据的存储、 处理提
供了可能。 以 Hadoop 为代表的大数据技术为基于大数据的
高校毕业生就业决策支持系统的设计提供了技术支持。 对基
于大数据的高校毕业生就业决策支持系统可基于 Hadoop 的
框架来实现。
3.2 基于大数据的高校毕业生就业决策支持系统的
功能需求分析
(1) 对高校毕业生就业情况进行分析, 产生大学毕业
生就业质量年度分析报告;
(2) 对高校毕业生就业的热点和发展趋势分析;
(3) 对就业整体趋势进行预测;
(4) 智能化的推荐, 为高校毕业生进行个性化就业推
荐 [7-9]。
3.3 基于大数据的高校毕业生就业决策支持系统的
设计
高校毕业生就业决策支持系统按照“基于 Hadoop 的大
数据决策支持系统” 体系结构进行设计, 其基础层、 数据存
储层、 分析层和决策支持层的具体功能如下:
基础层: 数据来源于毕业生生源信息数据库, 毕业生就
业信息数据库, 就业信息网站的招聘信息, 双选会, 公务员、事业单位的招考信息等, 这些信息数据既包含了关系数据库
中存储的结构化数据, 也包含了网站上的半结构化、 非结构
化信息。 基础层需要对这些异构的数据进行采集、 清理、 预
处理, 再将其输出到数据存储层的 HDFS 中。
数据存储层: 数据存储层不仅要能够存储海量的数据,
更重要的是为其上层——分析层能够更好地对数据进行分
析提供支持。 数据仓库是为了决策需要而设计的, 是面向
主题的、 集成的。 数据仓库的设计是数据存储层设计的重点。
在本系统中, 依据其功能需求, 设定数据仓库面向毕业生
就业的职业流向和毕业生就业的地域流向两大主题。 数据
仓库的逻辑结构采用雪花模型进行设计, 如图 3 所示, 它
包括两个基本的元素: 事实表和维度表, 事实表用来存放
要分析的全部数据, 维度表中的维度是分析问题的角度(例
如: 性别、 专业、 学历层次、 地域、 职位、 行业、 就业单
位的性质等)。
 分析层: 针对数据库和数据仓库的 OLTP 和 OLAP 操
作可生成决策所需的各类统计数据, 但决策者使用决策支持
系统不是直接依靠数据库子系统中的数据进行决策, 而是在
很大程度上利用模型库中的模型进行决策。 因此, 模型库是
分析层设计的重点。 根据本系统的需求, 按照“选择模型 /
自定义模型—训练模型—评估模型—优化模型” 的步骤, 利
用 Mahout 中的算法建立模型库中的模型, 如: 构建关系模
型对大学生就业价值取向与就业流向(职业流向、 地域流向)
的关系进行研究, 构建时间序列模型对就业整体趋势进行预
测, 构建聚类模型对掌握高校毕业生就业的热点进行分析,
构建推荐模型对大学生进行个性化就业推荐。
决策支持层: 利用 Python 实现该层的人机交互功能,
通过人机交互调用模型库中的模型或进行数据查询, 引导决
策者进行决策。
4 结 论
大数据技术正在成为推动社会发展、 进步的新力量,
基于大数据的高校毕业生就业决策支持系统利用大数据技
术分析就业形势和毕业生特点, 不仅能帮助毕业生调整就
业预期 / 找准就业定位 , 还可以为高校的专业设置和招生计
划的决策提供指导。
上一篇:基于现代学徒制模式下的毕业实践改革与创新 ——以模具设计与制造专业为例
下一篇:教育实习与毕业论文一体化之置换课程教学大纲的设计与思考 ——以教学名师观摩课程为例
相关推荐:
分析层: 针对数据库和数据仓库的 OLTP 和 OLAP 操
作可生成决策所需的各类统计数据, 但决策者使用决策支持
系统不是直接依靠数据库子系统中的数据进行决策, 而是在
很大程度上利用模型库中的模型进行决策。 因此, 模型库是
分析层设计的重点。 根据本系统的需求, 按照“选择模型 /
自定义模型—训练模型—评估模型—优化模型” 的步骤, 利
用 Mahout 中的算法建立模型库中的模型, 如: 构建关系模
型对大学生就业价值取向与就业流向(职业流向、 地域流向)
的关系进行研究, 构建时间序列模型对就业整体趋势进行预
测, 构建聚类模型对掌握高校毕业生就业的热点进行分析,
构建推荐模型对大学生进行个性化就业推荐。
决策支持层: 利用 Python 实现该层的人机交互功能,
通过人机交互调用模型库中的模型或进行数据查询, 引导决
策者进行决策。
4 结 论
大数据技术正在成为推动社会发展、 进步的新力量,
基于大数据的高校毕业生就业决策支持系统利用大数据技
术分析就业形势和毕业生特点, 不仅能帮助毕业生调整就
业预期 / 找准就业定位 , 还可以为高校的专业设置和招生计
划的决策提供指导。
上一篇:基于现代学徒制模式下的毕业实践改革与创新 ——以模具设计与制造专业为例
下一篇:教育实习与毕业论文一体化之置换课程教学大纲的设计与思考 ——以教学名师观摩课程为例
相关推荐: