
领取口令:免费查重

基于ARIMA模型的渔业经济预测及其优化
来源:论文查重 时间:2020-01-16 21:10:02
摘要:渔业作为国民经济的重要基础之一,对其进行预测十分必要。 本文采用时间序列 ARIMA 模型对渔业总产值进行
预测,根据模型预测结果进行误差分析。 考虑通货膨胀对预测模型的影响,利用居民消费价格指数(CPI)对模型进行进
一步优化。 进而以江苏省渔业总产值为例,将 1995—2014 年的数据作为训练样本,建立模型并结合 CPI 指数对其优化,
以 2015—2018 年数据作为测试样本,验证了优化模型具有较好的预测效果。
关键词:渔业总产值; ARIMA 模型; CPI 指数
0 引 言
自 20 世纪 90 年代以来,随着世界海洋经济的加
速发展,国家之间的海洋经济竞争呈现白热化的趋
势。 在世界海洋强国和大国中,海洋经济的 GDP 占
比大多在 7% ~15% 之间[1]。 从世界范围来看,海洋
经济发展的一个重要趋势是,人口、经济和产业不断
向沿海地区集中。 目前,全球有 60% 以上的人口和
近 70% 的大中城市位于沿海地区[2],这无疑是海洋
经济越来越具有吸引力的重要体现。 而在我国,海洋
开发历史悠久,海洋经济在国民经济中的地位日渐提高,海洋产业增加值占全国 GDP 的比重上升很快,海
洋产业对国民经济的贡献也越来越大。 进入 21 世纪
以来,伴随中国经济发展和资源需求的增长,也适时
调整了海洋经济发展战略。 2017 年,我国海洋生产
总值 77611 亿元,占国内生产总值的 9. 4% [3],成为
支撑经济增长的重要力量。 我国“十二五”规划中就
明确提出要“大力发展海洋经济”,“坚持海陆统筹,
制定并实施海洋发展战略,提髙海洋开发控制综合管
理能力”, 标志着我国 “ 海洋强国战略” 的全面实
施[4]。 而随着我国海洋经济的快速发展,关于海洋
产业及海洋经济的相关研究领域也逐渐引起重视并发展起来。 当前,我国关于海洋产业及海洋经济的相
关研究主要集中于 2 个方面。 首先在理论层面,主要
是对海洋渔业发展现状的分析、存在问题的探讨及发
展战略设计等方面的研究。 其次在实证层面的研究,
则主要集中在影响因素的分析和综合实力的测评。
对于整体海洋经济发展趋势的预测的研究则相对较
少,这极大地制约了海洋经济学科的发展。
目前国内对于海洋经济预测的定量方法主要包
括趋势外推法、灰色系统法以及成长曲线法。 趋势外
推法是长期趋势预测的主要方法,它是根据时间序列
的发展趋势,配合合适的曲线模型,外推预测未来的
趋势值。 所谓灰色系统理论,就是研究灰色系统的有
关建模、控模、预测、决策、优化等问题的理论。 基于
灰色系统理论的灰色模型主要有 GM(1,1)灰色微分
预测模型。 当原始时间序列隐含着指数变化规律时,
灰色模型 GM(1,1) 可成功地进行预测。 灰色模型
GM(1,1)用作短期预测时,一般能取得较高的精度。
而用作长期预测时,由于经济系统运行起伏较大,往
往产生较大的偏差也相对滞后,这极大地制约了海洋
经济学科的发展。 成长曲线是一条 S 型曲线,最初用
于描述生物生长,在生物学、系统分析、经济学及预测
学等领域中广泛应用。 由于产业成长与生命体类似,
也具有成长、成熟、衰退等特征,因此在经济预测中它
反映经济开始增长缓慢,随后增长加快,达到一定程
度后,增长率逐渐减慢,最后达到饱和状态的过程。
上述模型均可用于海洋渔业总产值的预测,其本
质都是基于时间序列模型构建的。 本文将使用时间
序列分析的方法去分析海洋渔业总产值的变动趋势。
然而传统的时间序列预测法因突出时间序列暂不考
虑外界因素影响,往往存在着预测误差的缺陷,这种
误差的缺陷在经济现象上尤为明显。 其主要表现在
分析海洋渔业总产值的变动趋势时,将货币价值视为
固定不变,只分析渔业总产值随时间变动的而产生的
变化情况。 而事实上,货币价值在每年的实际价值是
不同的,若不考虑这部分因素就直接去构建海洋渔业
总产值的预测模型,将会使得最终预测结果与实际值
有较大误差。 因此,本文将通过探究同时期居民消费
价格指数的动态变化特征,打破传统时间序列模型的
构建局限,将时间以及居民消费价格变动指数这 2 个
主要影响因素结合起来,最终构建出误差更小更精确
的海洋渔业总产值预测模型。
1 数学模型
1. 1 模型选择说明
本文主要基于时间序列分析来对我国短期渔业
总产值进行分析预测。 时间序列是指将某种现象某
一个统计指标在不同时间上的各个数值,按时间先后顺序排列而形成的序列。 时间序列分析是指根据过
去的变化趋势预测未来的发展,它的前提是假定事物
的过去延续到未来[5]。 对于我国每年的海洋渔业总
产值历史数据来说,可以构成一个时间序列,利用历
史数据的变化趋势来预测未来的渔业总产值。
由于不同的时间序列有不同的特征,需要使用不
同的时间序列预测方法[6]。 ARIMA 模型是时间序列
预测方法的一种,它是处理带有趋势、季节性等因素
的模型类[6]。 考虑到渔业总产值是一个有趋势,并
且受季节因素影响的一个指标,因此本文采用 ARI
MA 模型对我国海洋渔业总产值进行分析,得出其规
律性,并预测其未来值。
1. 2 时间序列模型
ARIMA 模型,全称为自回归积分滑动平均模型,
是指将非平稳时间序列转化为平稳时间序列,然后将
因变量仅对它的滞后值以及随机误差项的现值和滞
后值进行回归所建立的模型。 其根据是原序列是否
平稳以及回归中所含部分的不同,包括移动平均过程
(MA)、自回归过程(AR)、自回归移动平均过程(AR
MA)以及 ARIMA 过程。 其中 AR 是自回归,p 为自回
归项;MA 为移动平均,q 为移动平均项数,d 为时间
序列成为平稳时所做的差分次数。
1. 3 确定时间序列模型
图 1 为确定时间序列模型流程图[5,8-9,11-13]。
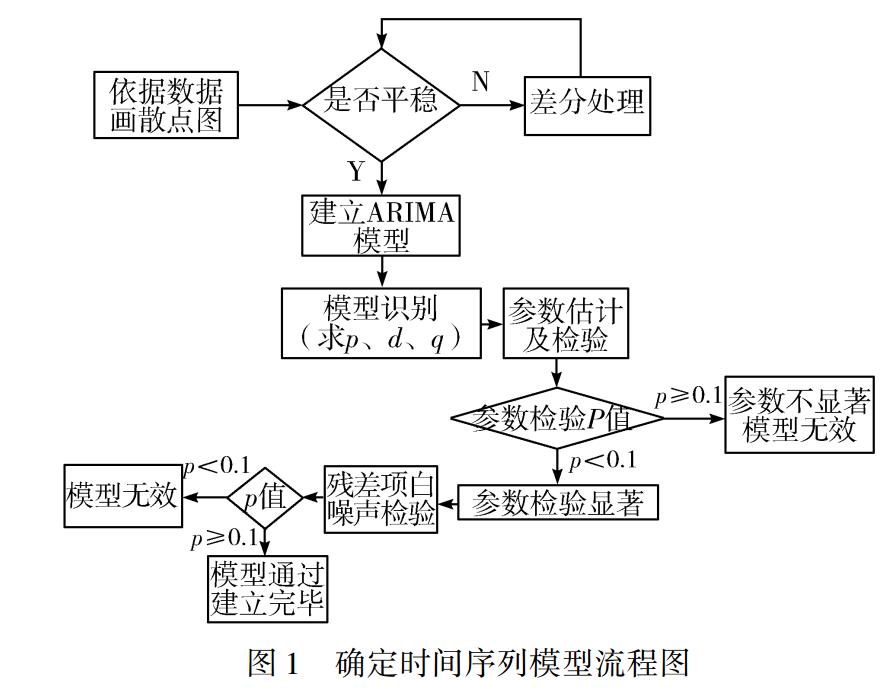 如果模型有效,则可以建立此模型:
首先通过数据画散点图,看数据是否平稳,如果
非平稳,则要进行差分处理;在有效的差分后若平稳,
则可建立 ARIMA 模型。 然后通过模型识别,确定 p、
d、q;再对模型的参数进行估计和检验,以及残差项白
噪声检验。 至此模型建立完毕[14-15]。
考虑到渔业总产值数据受 CPI(居民消费价格指
数) 影响,因此通过历史 CPI 数据对初等模型进行
优化[18]。
根据上述 ARIMA 模型可知,t 期的预测值 Xt 受
BrX
t(0 < r ≤d,r∈N)的影响,因此本文通过消除 BrXt
期通货膨胀对 Xt 的影响,达到模型优化的目的。 优
化模型结构如下:
其中 ϕt 是 t 期的 CPI 指数,Xt 是 t 期渔业生产总值,
a
t 是随机误差。
优化模型是在基于时间序列模型参数估计完毕
的基础上,利用 t 期的 CPI 指数 ϕt 对模型(1) 进行
优化。
2 案例分析
以江苏省渔业总产值预测为例, 利用 1995—
2014 年江苏省渔业生产总值数据进行分析和模型训
练,并对 2015—2018 年的数据进行预测。
2. 1 数据简述
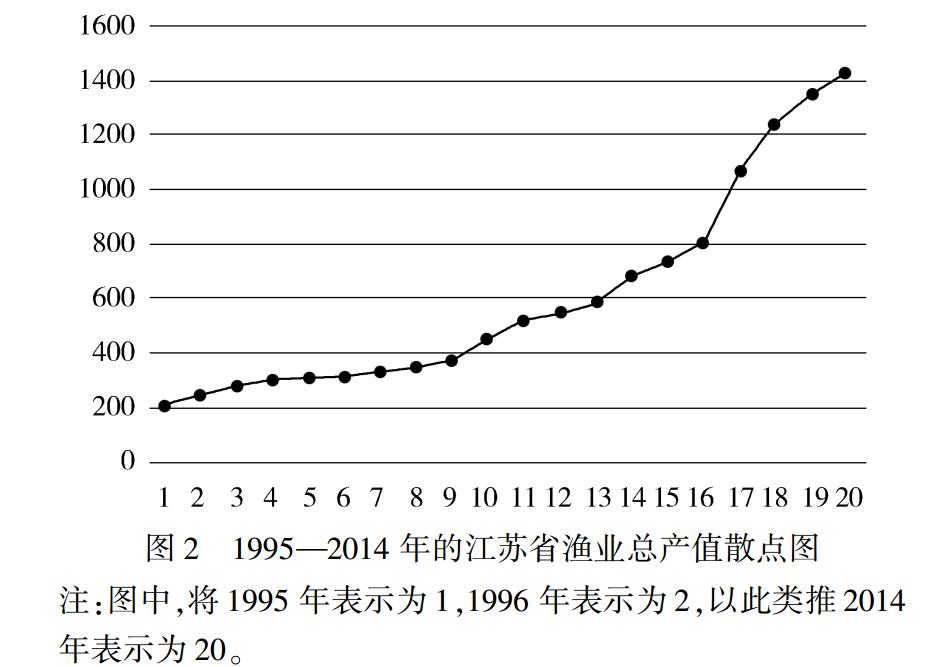
1995—2014 年这 20 年间的江苏海洋渔业生产总产值数据如表 1 所示。 图 2 展示了这 20 个观测值
的散点图。 易见,随着时间的增长渔业生产总产值也
随之增长。
如果模型有效,则可以建立此模型:
首先通过数据画散点图,看数据是否平稳,如果
非平稳,则要进行差分处理;在有效的差分后若平稳,
则可建立 ARIMA 模型。 然后通过模型识别,确定 p、
d、q;再对模型的参数进行估计和检验,以及残差项白
噪声检验。 至此模型建立完毕[14-15]。
考虑到渔业总产值数据受 CPI(居民消费价格指
数) 影响,因此通过历史 CPI 数据对初等模型进行
优化[18]。
根据上述 ARIMA 模型可知,t 期的预测值 Xt 受
BrX
t(0 < r ≤d,r∈N)的影响,因此本文通过消除 BrXt
期通货膨胀对 Xt 的影响,达到模型优化的目的。 优
化模型结构如下:
其中 ϕt 是 t 期的 CPI 指数,Xt 是 t 期渔业生产总值,
a
t 是随机误差。
优化模型是在基于时间序列模型参数估计完毕
的基础上,利用 t 期的 CPI 指数 ϕt 对模型(1) 进行
优化。
2 案例分析
以江苏省渔业总产值预测为例, 利用 1995—
2014 年江苏省渔业生产总值数据进行分析和模型训
练,并对 2015—2018 年的数据进行预测。
2. 1 数据简述
1995—2014 年这 20 年间的江苏海洋渔业生产总产值数据如表 1 所示。 图 2 展示了这 20 个观测值
的散点图。 易见,随着时间的增长渔业生产总产值也
随之增长。
 2. 2 数学建模
Step1 对年度渔业生产总值数据的时间序列进
行一阶差分[5]。
由图 2 可知,随着时间的增长,渔业生产总值也
随之增长,据此得出该时间序列成上升趋势,不平稳。
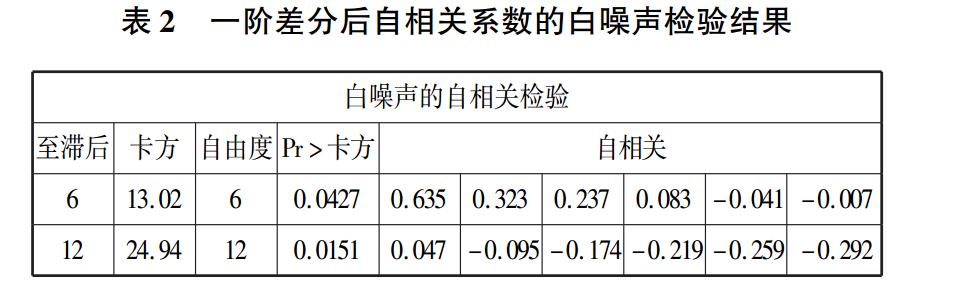
因此,对此时间序列进行一阶差分,得出结果见表 2。
由表2 可知,如果给定 α =0. 05,白噪声检验的 P
值均小于 0. 05,则表明白噪声检验显著,所以年度渔
业生产总值数据一阶差分之后是不平稳的。 所以需
要进行二阶差分。
2. 2 数学建模
Step1 对年度渔业生产总值数据的时间序列进
行一阶差分[5]。
由图 2 可知,随着时间的增长,渔业生产总值也
随之增长,据此得出该时间序列成上升趋势,不平稳。
因此,对此时间序列进行一阶差分,得出结果见表 2。
由表2 可知,如果给定 α =0. 05,白噪声检验的 P
值均小于 0. 05,则表明白噪声检验显著,所以年度渔
业生产总值数据一阶差分之后是不平稳的。 所以需
要进行二阶差分。
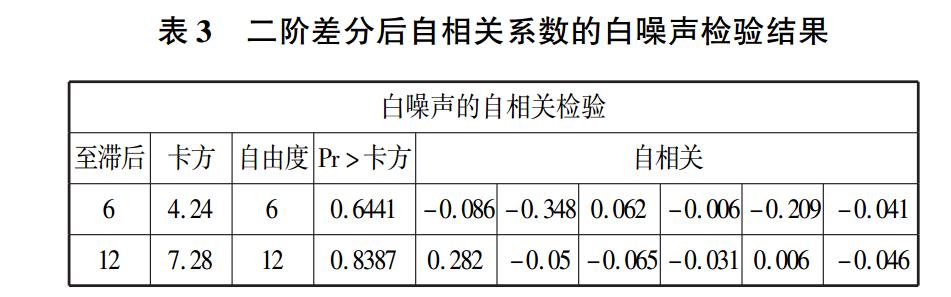
 α 对年度渔业生产总值数据的时间序列进行二
阶差分[16],所得结果见表 3。
α 对年度渔业生产总值数据的时间序列进行二
阶差分[16],所得结果见表 3。
 由表3 可知,如果给定 α =0. 05,白噪声检验的 P
值均大于 0. 05,则表明白噪声检验不显著,所以年度
渔业生产总值数据二阶差分之后是平稳的。
由表3 可知,如果给定 α =0. 05,白噪声检验的 P
值均大于 0. 05,则表明白噪声检验不显著,所以年度
渔业生产总值数据二阶差分之后是平稳的。
 Step2 模型的识别。
1)计算扩展的样本自相关函数并利用其估计值
进行模型识别[17]。
在 SAS 中,通过 ARIMA 过程的 IDENTIFY 语句,
在该语句中加入 ESACF 关键词,可得出运行结果,见表4.
Step2 模型的识别。
1)计算扩展的样本自相关函数并利用其估计值
进行模型识别[17]。
在 SAS 中,通过 ARIMA 过程的 IDENTIFY 语句,
在该语句中加入 ESACF 关键词,可得出运行结果,见表4.
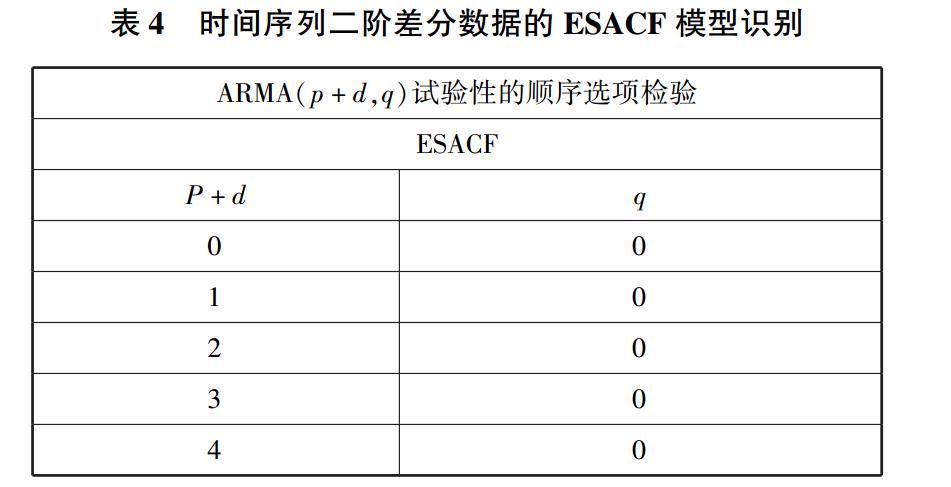 从表 4 中可以看出 p + d = 0、q = 0 时的模型最
佳,其次是 p + d = 1、q = 0 的模型。 因为对于该数据
已经进行了二阶差分,上述结果是针对序列二阶差分
之后的数据而言的,故此时的 d =0。 最优结果为 p =
0、q =0,次优结果为 p + d = 1、q = 0 的模型。 选择最
优结果 p =0、q =0,即为 ARIMA(0,2,0)。
2)利用典型相关系数平方估计值进行模型识别。
在 SAS 中,通过 ARIMA 过程的 IDENTIFY 语句,
在该语句中加入 SCAN 关键词,可得出运行结果,见
表 5。
从表 4 中可以看出 p + d = 0、q = 0 时的模型最
佳,其次是 p + d = 1、q = 0 的模型。 因为对于该数据
已经进行了二阶差分,上述结果是针对序列二阶差分
之后的数据而言的,故此时的 d =0。 最优结果为 p =
0、q =0,次优结果为 p + d = 1、q = 0 的模型。 选择最
优结果 p =0、q =0,即为 ARIMA(0,2,0)。
2)利用典型相关系数平方估计值进行模型识别。
在 SAS 中,通过 ARIMA 过程的 IDENTIFY 语句,
在该语句中加入 SCAN 关键词,可得出运行结果,见
表 5。
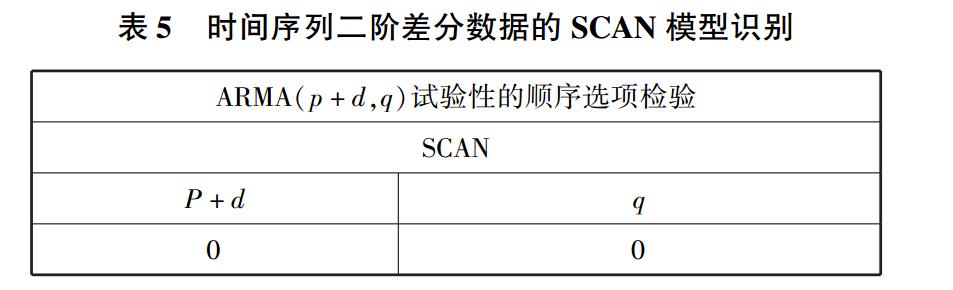 从表 5 中可以看出 p + d =1、q =0 时的模型是最
优选择,即模型为 ARIMA(0,2,0)。
综上 2 种方法,可得出年度渔业生产总值数据的
时间序列模型为 ARIMA(0,2,0)。
Step3 模型残差白噪声检验。
在对该时间序列进行识别并确定模型之后,还需
要保证其残差项无自相关性,即需对残差进行白噪声
检验。 如果模型残差项非白噪声,则需要重新对模型
进行识别。 模型残差项的白噪声检验见表 6。
从表 5 中可以看出 p + d =1、q =0 时的模型是最
优选择,即模型为 ARIMA(0,2,0)。
综上 2 种方法,可得出年度渔业生产总值数据的
时间序列模型为 ARIMA(0,2,0)。
Step3 模型残差白噪声检验。
在对该时间序列进行识别并确定模型之后,还需
要保证其残差项无自相关性,即需对残差进行白噪声
检验。 如果模型残差项非白噪声,则需要重新对模型
进行识别。 模型残差项的白噪声检验见表 6。
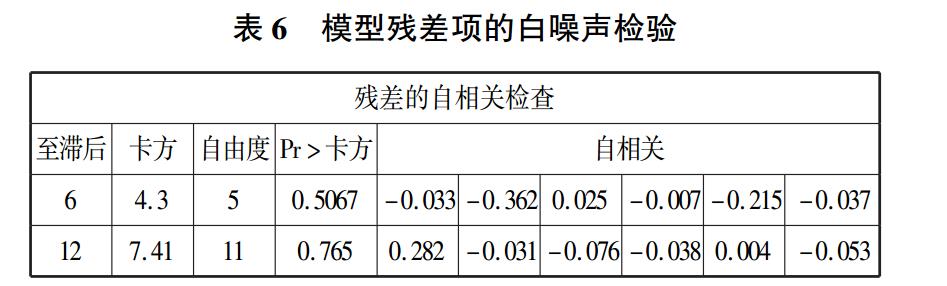 残差项白噪声检验的原假设为残差项是白噪声,
备选假设为非白噪声。 各滞后期的残差项不存在相
关,即 Pr > 卡方均远大于 α = 0. 05,可以认为该模型
的残差项为白噪声。 因此 ARIMA(0,2,0)模型对于
年度渔业生产总值数据二阶差分序列而言是合适
的[18,21-23]。
2. 3 模型预测
根据上述所得模型,利用 SAS 的 forecast 语句对
2015—2018 年江苏省海洋渔业总产值进行预测,预
测结果如表 7 所示。
残差项白噪声检验的原假设为残差项是白噪声,
备选假设为非白噪声。 各滞后期的残差项不存在相
关,即 Pr > 卡方均远大于 α = 0. 05,可以认为该模型
的残差项为白噪声。 因此 ARIMA(0,2,0)模型对于
年度渔业生产总值数据二阶差分序列而言是合适
的[18,21-23]。
2. 3 模型预测
根据上述所得模型,利用 SAS 的 forecast 语句对
2015—2018 年江苏省海洋渔业总产值进行预测,预
测结果如表 7 所示。
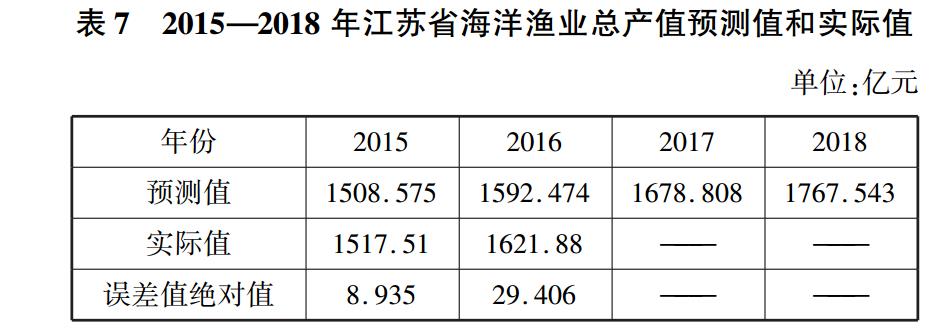 通过预测可以发现,采用 ARIMA(0,2,0)模型所进
行的预测,某些年份的预测值与实际值仍存在较大的误
差,因此,本文考虑到国内通货膨胀这个因素的影响,根
据上述模型结合我国 CPI 的变动对模型进行修正。
2. 4 模型优化
为了能较好地分析居民消费价格指数与年度渔
业生产总值模型之间的关系, 在此, 同样 选 取 了
1995—2014 年在 20 年间的我国居民消费价格指数
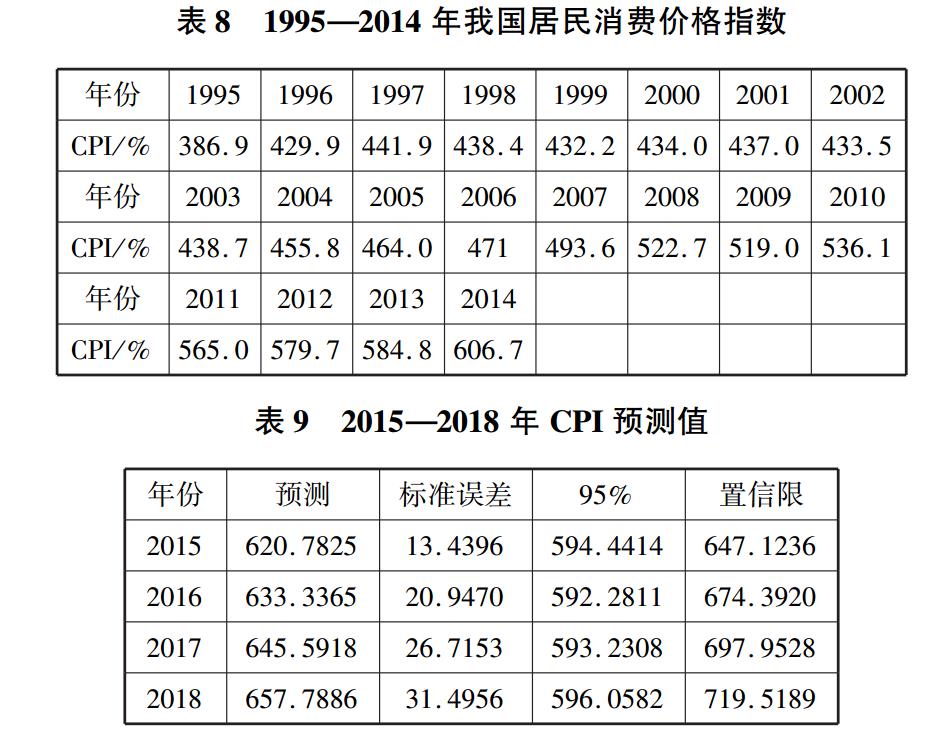
(CPI)这一数据,具体数据见表 8。 并利用 1995—
2014 年的 CPI 数据去预测 2015—2018 年的 CPI 值,
在此通过 ARMA(p,q)模型预测 CPI 值[19],通过 SAS
软件的计算,最终可以预测出 2015—2018 年 CPI 值
如表 9 所示。
通过预测可以发现,采用 ARIMA(0,2,0)模型所进
行的预测,某些年份的预测值与实际值仍存在较大的误
差,因此,本文考虑到国内通货膨胀这个因素的影响,根
据上述模型结合我国 CPI 的变动对模型进行修正。
2. 4 模型优化
为了能较好地分析居民消费价格指数与年度渔
业生产总值模型之间的关系, 在此, 同样 选 取 了
1995—2014 年在 20 年间的我国居民消费价格指数
(CPI)这一数据,具体数据见表 8。 并利用 1995—
2014 年的 CPI 数据去预测 2015—2018 年的 CPI 值,
在此通过 ARMA(p,q)模型预测 CPI 值[19],通过 SAS
软件的计算,最终可以预测出 2015—2018 年 CPI 值
如表 9 所示。
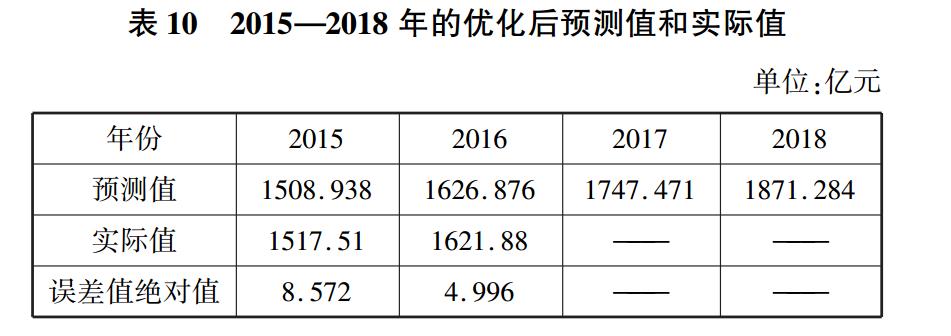
 根据上述优化后的模型,对每年数据进行预测,得到结果如表 10 所示。
根据上述优化后的模型,对每年数据进行预测,得到结果如表 10 所示。
 2. 5 模型评价
通过对预测误差进行优化前的模型和优化后的
模型的比较,得到如下结果,具体见表 11。
2. 5 模型评价
通过对预测误差进行优化前的模型和优化后的
模型的比较,得到如下结果,具体见表 11。
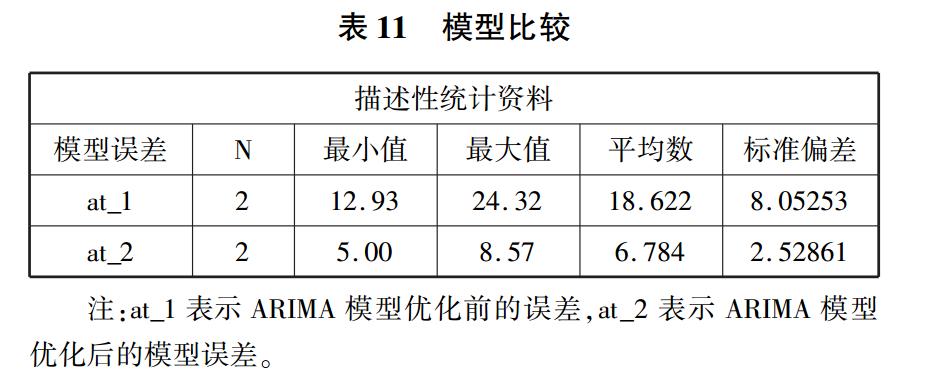 通过表 11 可以看出,优化后模型的误差均值比
优化前的更小,优化后的预测值更接近实际值,表明
优化后的模型精确度优于优化前的模型,因此上述优
化模型是合理的。
但由于每年政府出台的政策变化,数据本身存在
误差,以及海洋渔业生产受气候等诸多干扰因素的影
响,使得最终优化后的模型所做出的预测与实际值仍
存在一定偏差,因此在模型中加入每期的干扰因素 β:
其中 βt - 1是 t -1 期的干扰因素,βt - 2是 t -2 期的干扰
因素。
这一模型,对于未来江苏省海洋渔业生产总产值
的预测仍具有较大的参考价值。
3 结束语
本文采用 ARIMA 模型对海洋渔业总产值进行分
析。 由于渔业总产值数据受 CPI 指数的影响,因此通
过历史 CPI 数据对初等模型进行优化。 本文以江苏
省渔业总产值为例,通过 1995—2014 年的历史数据,
对其建立时间序列模型,预测出 2015—2018 年的渔
业总产值。 再利用 CPI 指数对模型优化, 预测出
2015—2018 年的渔业总产值。 通过对优化前与优化
后的预测模型进行比较,发现优化后的模型预测误差
更小,表明优化后的模型预测更精确。
上一篇:高校大学生Word2007利用中常见问题及解决措施
下一篇:工程能力导向的三维度六环节工程管理人才培养实践
相关推荐:
通过表 11 可以看出,优化后模型的误差均值比
优化前的更小,优化后的预测值更接近实际值,表明
优化后的模型精确度优于优化前的模型,因此上述优
化模型是合理的。
但由于每年政府出台的政策变化,数据本身存在
误差,以及海洋渔业生产受气候等诸多干扰因素的影
响,使得最终优化后的模型所做出的预测与实际值仍
存在一定偏差,因此在模型中加入每期的干扰因素 β:
其中 βt - 1是 t -1 期的干扰因素,βt - 2是 t -2 期的干扰
因素。
这一模型,对于未来江苏省海洋渔业生产总产值
的预测仍具有较大的参考价值。
3 结束语
本文采用 ARIMA 模型对海洋渔业总产值进行分
析。 由于渔业总产值数据受 CPI 指数的影响,因此通
过历史 CPI 数据对初等模型进行优化。 本文以江苏
省渔业总产值为例,通过 1995—2014 年的历史数据,
对其建立时间序列模型,预测出 2015—2018 年的渔
业总产值。 再利用 CPI 指数对模型优化, 预测出
2015—2018 年的渔业总产值。 通过对优化前与优化
后的预测模型进行比较,发现优化后的模型预测误差
更小,表明优化后的模型预测更精确。
上一篇:高校大学生Word2007利用中常见问题及解决措施
下一篇:工程能力导向的三维度六环节工程管理人才培养实践
相关推荐: